Introduction
It has been almost a year since the publication of the BERT paper1. By now we already witnessed models that surpassed BERT in accuracy but none of them in such spectacular fashion as BERT.
If you don’t know what BERT is, there is no need to worry we will get there, and we will get there gently…
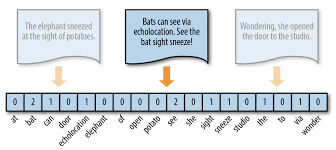
To understand why BERT is so important one has to understand how computers process text. In the early days this was usually done by so called one-hot encoding.
Namely if we were to create text classification model we would encode every word from some fixed vocabulary by vector of length equal to vocabulary size filled with 0’s everywhere but one entry:

Once we had word representation we could in principle create document representation by adding those vectors for all word in text. This would be something we call bag-of-words representation.
Engineers would later on use this representation to build for example logistic regression to detect whether document belongs to some pre-defined class. As long as words critical for the algorithm accuracy are limited in number this would work just fine.
Unfortunatelly this is usually not the case. Good example is a sentiment classification task. Human emotions can be in principle expressed in so many ways that good algorithms would require vocabulary so big that any text in our training sample would be most likely represented as completely different bag of words thus making classical learning unfeasible. It’s probably a little exagerated but you probably see now where the problem is.
Here is an accuracy of logistic regression using this approach on IMDB Sentiment Dataset[^3]:
github gist
First word embeddings
In 2013 Team of researchers lead by Thomas Mikolov published algorithm2 that enabled finding more compact representation of words preserving their meaning. This was pretty big deal for machine learning community working around text processing.
First of all this representation could be easily learned from untagged data. Simple neural network predicting word using information about surrounding words is sufficient. This representation was orders of magnitude smaller than typical NLP problems vocabulary.
More importantly it was also encoding some notion of semantic similarity. As usually with dimensionality reduction methods it was not perfect but it let algorithms to extrapolate from words seen during training to their semantic equivalents.
Here is an example of graphical representation of embeddings projected on two dimensional plane:
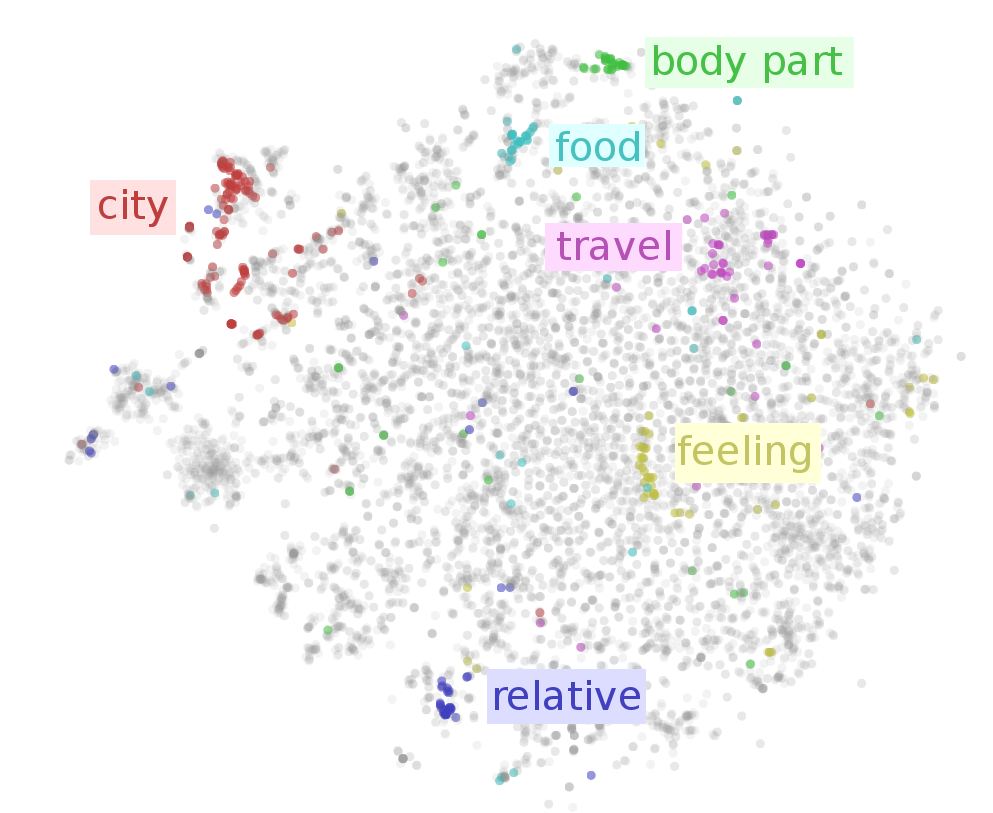
It let the algorithms to achieve accuracy never seen before. Practitioners soon realised that there is still one major obstacle in the way. Mikolov embeddings where by design static. The word bank had the same embedding independently whether it was meant to represent financial institution or for example “river bank”.
Enter BERT.
Bidirectional Transformers a.k.a. BERT
Basically where Mikolov algorithm was only learning word embedding BERT learns also how to additionally take into an account surrounding words to correct its basic representation. Architecture of BERT is an engineering feat on its own but it is enough to know that it
import tensorflow as tf
print(tf.__version__)
from models.official.bert import modeling
from models.official.bert import tokenization