You got me thinking about Watson and its unprecedented flexibility in analyzing different data sources (at least according to IBM). So how difficult it would be to analyse sentiment of one of my favorites books using R? Pretty easy actually - all thanks to new package tidytext by Julia Silge and David Robinson…
The tidy text format
Tidy text format is defined as a table with one-term-per-row. In short it is just tidy textual data which enables to use tidyverse tools to clean and transform data. More about conceptual underpinnings creation of tidytext package can be found in the online book:
http://tidytextmining.com/tidytext.html
Parsing data to the tibble format
I parsed one of the websites that offers LOTR trilogy online. After some pretty basic operations on html source I extracted full text along with chapter names and book parts and book titles:
## # A tibble: 6 × 4
## book part chapter
## <chr> <chr> <fctr>
## 1 1. Fellowship of the Ring Book I A Long-expected Party
## 2 1. Fellowship of the Ring Book I A Long-expected Party
## 3 1. Fellowship of the Ring Book I A Long-expected Party
## 4 1. Fellowship of the Ring Book I A Long-expected Party
## 5 1. Fellowship of the Ring Book I A Long-expected Party
## 6 1. Fellowship of the Ring Book I A Long-expected Party
## # ... with 1 more variables: text <chr>
with field text simply containing lines of text from the books:
## # A tibble: 6 × 1
## text
## <chr>
## 1 When Mr. Bilbo Baggins of Bag End announced that h...
## 2 celebrating his eleventy-first birthday with a par...
## 3 there was much talk and excitement in Hobbiton....
## 4 Bilbo was very rich and very peculiar, and had bee...
## 5 for sixty years, ever since his remarkable disappe...
## 6 The riches he had brought back from his travels ha...
Sentiment analysis
One way to analyze the sentiment of a text is to consider the text as a combination of its individual words and the sentiment content of the whole text as the sum of the sentiment content of the individual words. Since LOTR is naturally divided into chapters we can apply sentiment analysis to them and plot their sentiment scores.
The three general-purpose lexicons available in tidytext package are
- AFINN from Finn Årup Nielsen,
- bing from Bing Liu and collaborators, and
- nrc from Saif Mohammad and Peter Turney.
I will use Bing lexicon which is simply a tibble with words and positive and negative words:
get_sentiments("bing") %>% head
## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 2-faced negative
## 2 2-faces negative
## 3 a+ positive
## 4 abnormal negative
## 5 abolish negative
## 6 abominable negative
and this is how you run sentiment analysis tidytext way:
lotr %>%
# split text into words
unnest_tokens(word, text) %>%
# remove stop words
anti_join(stop_words, by = "word") %>%
# add sentiment scores to words
left_join(get_sentiments("bing"), by = "word") %>%
# count number of negative and positive words
count(chapter, book, sentiment) %>%
spread(key = sentiment, value = n) %>%
ungroup %>%
# create centered score
mutate(sentiment = positive - negative -
mean(positive - negative)) %>%
select(book, chapter, sentiment) %>%
# reorder chapter levels
mutate(chapter = factor(as.character(chapter),
levels = levels(chapter)[61:1])) %>%
# plot
ggplot(aes(x = chapter, y = sentiment)) +
geom_bar(stat = "identity", aes(fill = book)) +
theme_classic() +
theme(axis.text.x = element_text(angle = 90)) +
coord_flip() +
ylim(-250, 250) +
ggtitle("Centered sentiment scores",
subtitle = "for LOTR chapters")
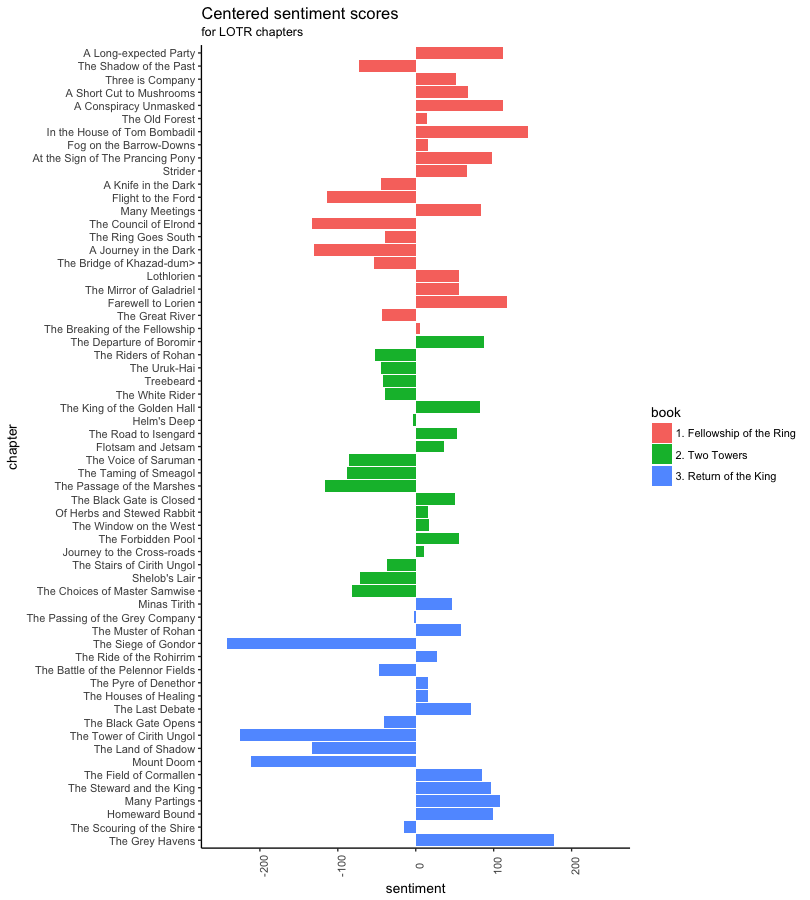
It’s pretty neat if you ask me.
Code for this post can be found here: github